A Report on How Big Data Tools Should Be Used and For
Introduction
Big Data refers to the application of specialized technologies and techniques to synthesize vast sets of data (Lynch, 2008). The data usually processed is too large and complex that they become cumbersome to prepare by use of typically available management tools (Wang et al., 2018). This work is a report to be presented to the University’s IT Department giving insights on how and where Big Data Tools should be used and for what rationales. The prospect of this report is to focus on knowledge and understanding in the intrigues of big data as studied and presented by various scholars in literature in the realm of informational directories on the internet. Besides, the report aims at comprehending the benefits of big data while envisioning information and data from ancient analytics into big data analytics, data storage and future predictions they can bestow upon not only academic institutions but also business processes. data analysis dissertation help is crucial for understanding and applying these concepts effectively.
Kitchin (2013) presents big data as interplay of technology, analysis, and mythology parameters whereby in technology, algorithmic accuracy and computation power is maximized in the quest to collect, synthesize, link and compare big data. In the analysis process, large amounts of data sets are drawn to establish patterns to make significant social, technical, legal and economic claims. Whereas, in mythology, the broad proposition that large data sets provide an elevated form of knowledge and intelligence which can inspire insights to situations which were previously impossible with the aura of accuracy, objectivity, and truth (Kocakulak, and Temizel, 2011).
Comparison of the Main Techniques Used
According to Appuswamy et al., (2013), the processing of vast amounts of information and data is not palatable with the traditional methods which make big data an excellent option. To address data growth explosion, different big data platforms have been enacted to assist containing and organize this data. These technologies according to Husain et al., (2009) are harnessed in conjunction with others. Of these many technologies; two of them namely MongoDB and Hadoop have become popular and share various similarities, but again differences in their processing nature and data storage. According to the Cap Theorem which was proposed by Eric Brewer in 1999, distributed computing cannot yield instant consistency, partition tolerance and availability while processing data. This theory can be likened to Big Data thresholds since it assists visualize bottlenecks which any particular solution will attain. Traditional RDBMS solutions offer availability and consistency and partition tolerance (Shvachko et al., 2010).

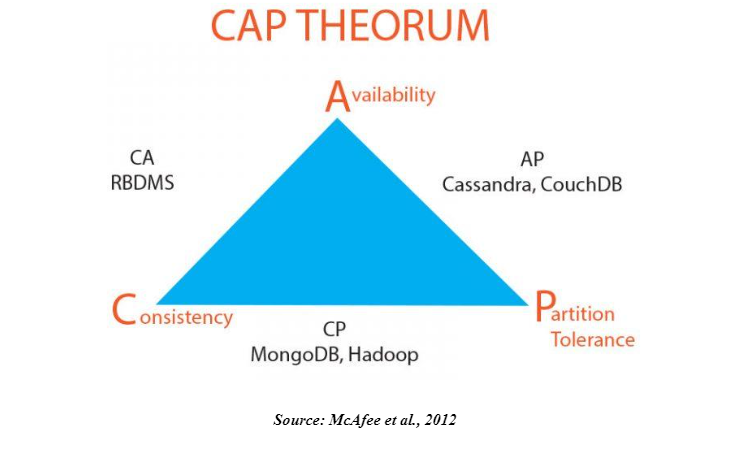
Both Hadoop and MongoDB succeed in offering partition tolerance and consistency but fail to function in conjunction with RDBMS while it comes to data availability. MongoDB is a general-purpose platform which is tailored to enhance or replace the present Relational Database Management Systems (RDBMS) thus giving it healthy and diversified use-cases. On the other hand, Hadoop ascended to become a platform for parallel synthesis of vast amounts of information astride clusters of commodity hardware (Chen, Mao, and Liu, (2014). Hadoop is a system comprising of a software system. The essential components of Hadoop include MapReduce and Hadoop Distributed File System which are written in Java. The secondary elements include a collection of Apache products such as Hive for interrogating data, Pig for analyzing large data sets, Sqoop for interfacing with different systems such as analytics, RBDMS, and BI; HBase, Oozie for scheduling Hadoop plans and Flume for preprocessing and aggregating data. Similar to MongoDB; Hadoop’s HBase database enhances horizontal scalability through the process of database sharding (Stonebraker et al., 2010). Based on platform strengths for prominent data use scenario, MongoDB’s is a more robust solution than Hadoop; and is capable of more considerable flexibility including a probability of replacing existing RDBMS (Zikopoulos, and Eaton, 2011). Besides, MongoDB’s is better in dealing with real-time analytics which grants it efficiency to deliver client-side data which is not in the case with Hadoop configurations. MongoDB’s geospatial indexing abilities make it ideal for practical geospatial analysis. On the other side, Hadoop is excellent in batch processing and analyzing long-running ETL jobs. The main strength of Hadoop is the fact that it was built for
the sake of big data whereas MongoDB became an option over time (Raghupathi, and Raghupathi, 2014). MapReduce refers to the programming model which seeks to permit one to process large amounts of data which is stored in Hadoop. The fundamental concept behind Hadoop is that data ought to be scalable and reliable as in the circumstance of a felony or network failure, and this is achieved by Hadoop’s framework utilizing Data Nodes and Name Nodes. The following diagram demonstrates fundamental Name Nodes and Data Nodes;
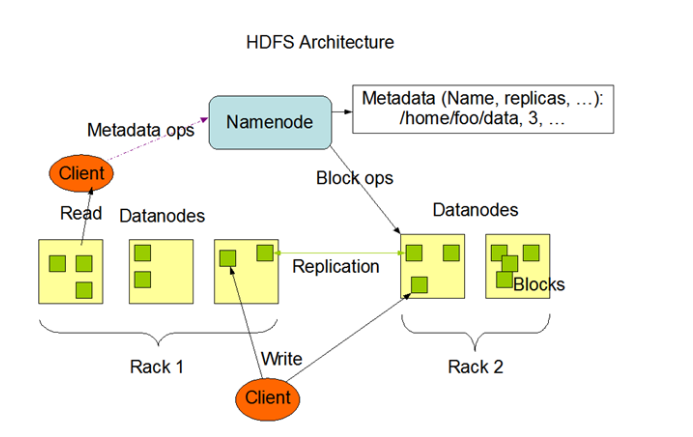
The architecture behind Data and Name Node is a construction of the master architecture whereby an individual stores the position the Name Node data and the other stores the data itself (Data Node). The information is divided into chunks of 64mb and stored in data block domains, and the storage register is retained at the Name Node. Data is replicated into three for reliability. Concerning scalability, the hardware can be increased simultaneously to assist in expanding the storage and make the system scalable (Wang et al., 2013). Big Data integrates high volume, high variety, and high velocity, making it highly contributive into the basketry of cost-effective processing, innovative types of analysis, and different business value. With Microsoft Excel, the program strives to better react with the demands of Big Data by offering processing tools which ease usability. The application of ad-hoc analysis tends to find information from the stores of high-velocity volumes (Schmarzo, 2013). Excel organizes more prescriptive and predictive experiences especially for unstructured information through the elements provided, much like assembling a disorder of social media into comprehensive details.
The implementation of external data to Excel is the construction of two distinct methods. The first method involves the importation of data to excel by use of Power Query which assist Excel to retrieve sets of connectors for DHFS, relational, and SaaS discourses. Power Query offers the avenue to change vast amounts of information only by bringing it into a structured and clean set. The second method involves exporting from an application to Excel. Excel has granted APIs for developers to formulate and enact this content for customers and prepare to reinforce it for future incorporation with the Excel Online (Sagiroglu, and Sinanc, 2013). Oracle’s exedata is a complete Big Data solution that is configured with both software and hardware configuration for consolidating and storing vast oracle’s databases. Oracles harness best hardware configuration from the Sun. According to Katalet al., (2013), oracles constitute features that make the appliance what it is commonly known for; like large storage capacity and high performance. Oracle bred forth intelligence into the hardware and storage layer of the machine which has resulted in query processing offload to the storage layer while dismounting up the software and database layer for other crucial tasks.
Criteria for Big Data
To take advantage of Big Data, the University Management ought to make sure that the applied technology stacks comprising of servers, storage, analysis software and networking capacity is updated periodically and up to the task. Moreover, there is a need to expand available resources to accommodate the Big Data tools or add new potentials to pave a way for continuous supply of resources. A successful Big Data supply chain is thus embedded on various criteria including storage, processing, analytics software, and networking. Concerning processing, servers meant for Big Data analytics constitute enough processing abilities to support this application. According to (Schmarzo, 2013) some analytics vendors including Splunk provide cloud processing options which are appealing to organizations that experiences periodic peaks. Big Data software provides efficiencies concerning data security on aspects related to ease of data use and data security. The main role of played by Big Data analytics software is to provide ground for predictive analytics which entails the analysis of present data to predict future trends on the same Chen, Chiang, and Storey (2012).
In relation to networking, Big Data software provide for a robust networking hardware to shuttle back vast amounts of information in Big Data. A number of institutions and organizations are presently running networking hardware which facilitates about 10-gigabit connections and these organizations can only induce mild applications such as integration of ne ports to accommodate the constraints of Big Data. Securing network transport system is a crucial phase I any upgrade especially in traffic that goes beyond network borders (Blanas et al., 2010).
Conclusion and Recommendations
The intrigues of Big Data are continually growing The Big Data environment shows excellent opportunity for business organizations in different realms of compete based on competitive advantage. The future of our university amongst other higher learning institutions is anchored on Big Data for the pursuit to safeguard the confidentiality, integrity, and retrieval of information. As we intend to foster our way forward, the University can apply the above-exemplified technologies as solutions for big data. Besides, the university should envisage applying a combination of these models; and conduct research to figure out which are the most applicable methods to sort out the tragedies of Big Data at hand. Moreover, the university should attach high value to data reliability and validity for easy and sustainable retrieval for application when needed. Big Data software which guarantees data validity, meaningfulness, authenticity and reliability should be given preference.
Missing values
In order to find missing values, the rows and columns in the data were selected independently and the done while all the rows and column selected. Then F5 was pressed to display a dialog box. In the box, special was selected then Black was checked then OK. The result showed all the space within the table had data or had been filled. This was repeated for the other datasheets with the observation remaining the same, where within the data table there were no missing data. The figure below shows a cutout sample of missing values observation
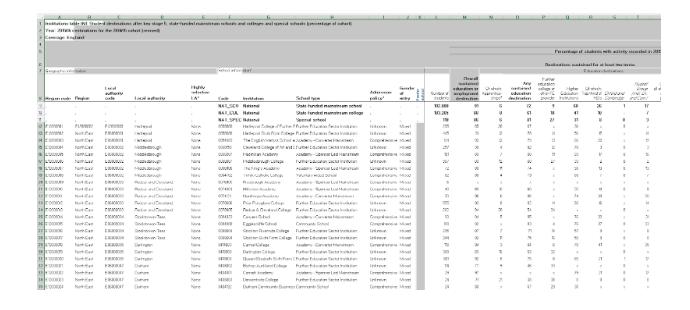
Second approach towards cleaning the data was checking for duplication and monitoring errors. The data were manipulate single row and column at a time using extrapolation and array formulas. For numerical data, summing, calculating mean, min, and max numbers were used in attempt to identify data that seem out of place. Sorting the by data region code it was found that there were no blank spaces (region code) sorted alphabetically (A-Z) same applied to all other school information. The lowest number of students in a school is1observed in (22 schools with majority being in South East region and 1 from East of England region with mixed schools were the most affected). NCG School in North East (Newcastle upon Tyne) has the highest number of students 2,155. Sorting by sustained employment destination, Focus School –Hindhead Campus has the highest 79 students while the lowest was Haberdashers’ Aske’s Boys School although some schools had X values. Using filter in excel it was possible to highlight the data specifically such as picking data from particular region or school type. Filtering the East Midland region, Oakland school has the highest student population with Nottingham having the highest students (92) with any sustained education destination. Although some school 14 schools in the region had zero (x) value.
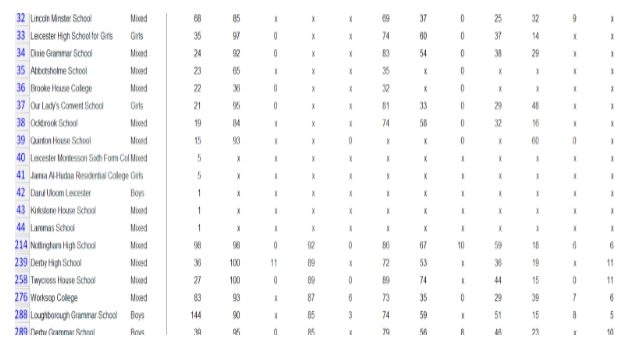
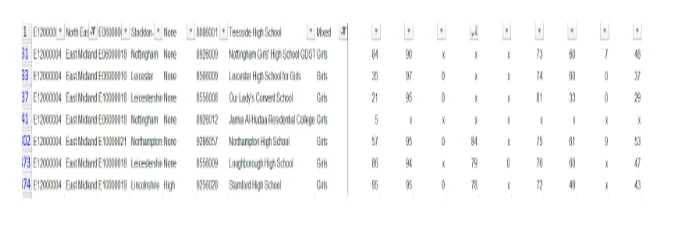
Similarly process is applicable to capturing the variation and mean of students as well as overall education or employment destination and sustained education captured in the key stage 5 data.
Looking for further insights on A case study on WBA plc? Click here.

References
- Appuswamy, R., Gkantsidis, C., Narayanan, D., Hodson, O. and Rowstron, A., 2013, October. Scale-up vs scale-out for hadoop: Time to rethink?. In Proceedings of the 4th annual Symposium on Cloud Computing (p. 20). ACM.
- Blanas, S., Patel, J.M., Ercegovac, V., Rao, J., Shekita, E.J. and Tian, Y., 2010, June. A comparison of join algorithms for log processing in mapreduce. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data (pp. 975-986). ACM.
- Chen, H., Chiang, R.H. and Storey, V.C., 2012. Business intelligence and analytics: From big data to big impact. MIS quarterly, 36(4).
- Chen, M., Mao, S. and Liu, Y., 2014. Big data: A survey. Mobile networks and applications, 19(2), pp.171-209.
- Husain, M.F., Doshi, P., Khan, L. and Thuraisingham, B., 2009, December. Storage and retrieval of large rdf graph using hadoop and mapreduce. In IEEE International Conference on Cloud Computing (pp. 680-686). Springer, Berlin, Heidelberg.
- Katal, A., Wazid, M. and Goudar, R.H., 2013, August. Big data: issues, challenges, tools and good practices. In 2013 Sixth international conference on contemporary computing (IC3) (pp. 404-409). IEEE.
- Kitchin, R., 2013. Big data and human geography: Opportunities, challenges and risks. Dialogues in human geography, 3(3), pp.262-267.
- Kocakulak, H. and Temizel, T.T., 2011, July. A Hadoop solution for ballistic image analysis and recognition. In 2011 International Conference on High Performance Computing & Simulation (pp. 836-842). IEEE.
- Lynch, C., 2008. Big data: How do your data grow?. Nature, 455(7209), p.28. McAfee, A., Brynjolfsson, E., Davenport, T.H., Patil, D.J. and Barton, D., 2012. Big data: the management revolution. Harvard business review, 90(10), pp.60-68.
- Provost, F. and Fawcett, T., 2013. Data science and its relationship to big data and data-driven decision making. Big data, 1(1), pp.51-59. Raghupathi, W. and Raghupathi, V., 2014. Big data analytics in healthcare: promise and potential. Health information science and systems, 2(1), p.3.
- Sagiroglu, S. and Sinanc, D., 2013, May. Big data: A review. In 2013 International Conference on Collaboration Technologies and Systems (CTS) (pp. 42-47). IEEE. Schmarzo, B., 2013. Big Data: Understanding how data powers big business. John Wiley & Sons.
- Shvachko, K., Kuang, H., Radia, S. and Chansler, R., 2010, May. The hadoop distributed file system. In MSST (Vol. 10, pp. 1-10).
- Stonebraker, M., Abadi, D., DeWitt, D.J., Madden, S., Paulson, E., Pavlo, A. and Rasin, A., 2010. MapReduce and parallel DBMSs: friends or foes?. Communications of the ACM, 53(1), pp.64-71.
- Wang, Y., Kung, L. and Byrd, T.A., 2018. Big data analytics: Understanding its capabilities and potential benefits for healthcare organizations. Technological Forecasting and Social Change, 126, pp.3-13.
- Wang, L., Tao, J., Ranjan, R., Marten, H., Streit, A., Chen, J. and Chen, D., 2013. G-Hadoop: MapReduce across distributed data centers for data-intensive computing. Future Generation Computer Systems, 29(3), pp.739-750.
- Zikopoulos, P. and Eaton, C., 2011. Understanding big data: Analytics for enterprise class hadoop and streaming data. McGraw-Hill Osborne Media.



What Makes Us Unique
- 24/7 Customer Support
- 100% Customer Satisfaction
- No Privacy Violation
- Quick Services
- Subject Experts